데이터 전처리 & 워드클라우드 시각화 실습 (Python)
by EunHye Jung
이 글은 아래 참조 사이트를 기반으로 이해한 내용을 개인적인 학습을 목적으로 정리한 것이며, 오역이나 잘못된 내용이 있을 수 있습니다.
Numpy
- 파이썬에서 numpy는 다차원 배열을 처리하는데 유용한 기능을 제공하는 라이브러리이다.
- numpy에서 배열은 동일한 타입을 가지며, 배열의 차원을
rank라 하며, 각 차원의 크기를 튜플로 표시하는 것은shape라고 한다.
예를 들어, 행이 2이고 열이 3인 2차원 배열에서 rank는 2이고, shape는 (2,3)이 된다.
ex)
import numpy as np
np_2d = np.array( [[ 1.73, 1.68, 1.71, 1.89, 1.79],
[ 65.4, 59.2, 63.6, 88.4, 68.7]])
# array( [[ 1.73, 1.68, 1.71, 1.89, 1.79]
# [ 65.4, 59.2, 63.6, 88.4, 68.7]])
np_2d.shape
# (2,5)
Pandas
- pandas는 데이터 분석, 데이터 처리 등을 쉽게 하기 위해 만들어진 파이썬 패키지.
- numpy를 기반으로 만들어졌다.
- 파이썬의 기능을 다음과 같다.
- 축의 이름을 따라 데이터를 정렬할 수 있는 자료구조
- 다양한 방식으로 색인된 데이터를 핸들링 가능한 기능.
- 통합된 시계열 기능
- 시계열, 비시계열 데이터를 모두 다룰 수 있는 자료구조
Pandas의 자료 구조
- Series
1차원 배열같은 구조.
복수의 행(row)으로 이루어진 하나의 열(column) 또는 복수의 열(columns)로 이루어져 있음.
obj = Series ([4, 7, -5, 3])
#0 4
#0 7
#2 -5
#3 3
#dtype : int64
print(obj.values)
# [ 4 7 -5 3]
print(obj.index)
# Rangeindex(start = 0, stop = 4, step = 1)
obj2 = Series([4, 7, -5, 3], index = ['d', 'b', 'a', 'c'])
obj2
# d 4
# b 7
# a -5
# c 3
dtype: int64
obj2.index
# Index(['d', 'b', 'a', 'c'], dtype = 'object')
obj2['a']
# -5
- Dataframe
하나의 열이 여러개가 모이면, 우리가 잘아는 액셀의 스프레드시트 형태라고 볼 수 있다.
DataFrame은 이러한 스프레드시트의 형식의 자료구조를 가진다.
각 열(column)에서는 서로 다른 종류의 값(숫자, 문자열)등을 가질 수 있다.
Series가 복수개로 합쳐진 것이라고 보면된다.
import pandas as pd
data = { 'state' : [ 'Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada' ],
'year' : [2000, 2001, 2002, 2001, 2002, 2003],
'pop' : [ 1.5, 1.7, 3.6, 2.4, 2.9, 3.2]
}
frame = pd.DataFrame(data)
frame
# state year pop
# 0 Ohio 2000 1.5
# 1 Ohio 2001 1.7
# 2 Ohio 2002 3.6
# 3 Nevada 2001 2.4
# 4 Nevada 2002 2.9
# 5 Nevada 2003 3.2
데이터 전처리 실습해보기
` IMDB 영화 리뷰를 로딩하여 데이터 전처리 과정을 거친 후 워드 클라우드로 표현해보자 `
데이터 읽어오고 데이터 정보 조회해보기
import pandas as pd
# 레이블인 sentiment가 있는 학습 데이터
train = pd.read_csv('data/labeledTrainData.tsv', header=0, delimiter='\t', quoting=3)
train.head()
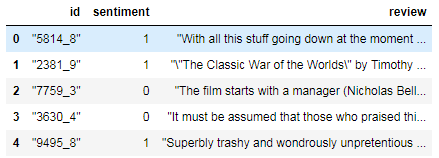
- pandas.read_csv에서 quoting = 3으로 설정해주면 인용구(따옴표)를 무시하게 해준다.
header = 0으로 설정하면 헤더값 표시, 1로 설정하면 헤더값 없이 데이터값이 바로 출력됨. - pandas.DataFrame.head
처음부터 n까지의 행을 반환해줌, 파라미터값으로 n을 입력할 수 있지만, 디폴트값은 5
# 레이블이 없는 테스트 데이터
test = pd.read_csv('data/testData.tsv', header = 0, delimiter = '\t', quoting=3)
test.head()

train.column.values
# array(['id', 'sentiment', 'review'], dtype = object)
train.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 25000 entries, 0 to 24999
# Data columns (total 3 columns):
# id 25000 non-null object
# sentiment 25000 non-null int64
# review 25000 non-null object
# dtypes: int64(1), object(2)
# memory usage: 586.0+ KB
train['review'][0][:700] # review의 첫번째행의 값을 700자까지 출력
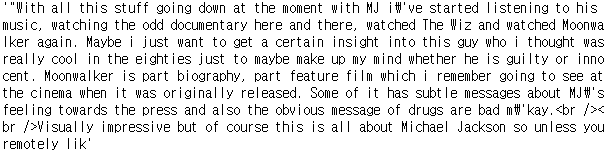
-> review 데이터 값에 html 태그가 섞여있기 때문에 이를 정제해주어야 한다.
데이터 정제 (Data Cleaning and Text Prepocessing)
기계가 텍스트를 이해할 수 있도록 텍스트를 정재해준다.
- BeautifulSoup(뷰티풀숩)을 통해 HTML 태그 제거
- 정규표현식으로 알파벳 이외의 문자를 공백으로 치환
- NLTK 데이터를 사용해 불용어(stopword) 제거
- 어간추출(스테밍 Stemming)과 음소표기법(Lemmatizing)의 개념을 이해하고, SnowballStemmer를 통해 어간 추출
텍스트 데이터 전처리 이해하기
-
정규화(Normalization) (입니다 ㅋㅋㅋ -> 입니다, 샤릉해 -> 사랑해)
한국어를 처리하는 예시입니닼ㅋㅋㅋㅋ -> 한국어를 처리하는 예시입니다 ㅋㅋ -
토큰화(Tokenization)
한국어를 처리하는 예시입니다 ㅋㅋ
-> 한국어Noun,를Josa,처리Noun,하는(Verb),예시(Noun),입(Adjective),니다(Emoi),ㅋㅋ(KoreanParticle) -
어근화(Stemming) (입니다 -> 이다)
입니다 -> 이다 한국어를 처리하는 예시입니다 ㅋㅋ
-> 한국어Noun,를Josa,처리Noun,하다(Verb),예시(Noun),이다(Adjective), ㅋㅋ(KoreanParticle) -
어구 추출(Pharse Extraction)
한국어를 처리하는 예시입니다 ㅋㅋ -> 한국어, 처리, 예시, 처리하는 예시
BeautifulSoup이 설치되어 있지 않으면 우선 설치해준다.
BeatuifulSoup은 HTML, XML 파일에서 원하는 데이터를 손쉽게 파싱해주는 라이브러리이다.
!pip install BeautifulSoup4
설치 및 버전 확인
!pip show BeautifulSoup4
BeautifulSoup을 이용하여 HTML 태그 정제 및 확인
from bs4 from BeautifulSoup
example1 = BeautifulSoup(train['review'][0], "html5lib")
print(train['review'][0][:700]) # 원본데이터
example1.get_text()[:700] # html 태그가 정제된 데이터

정규표현식을 사용해서 특수문자 제거하기
import re
# 소문자와 대문자가 아닌것은 공백으로 대체
letters_only = re.sub('[^a-zA-Z]', ' ', example1.get_text())
letters_only[:700]

모든 문자를 소문자로 변환하고, 토큰화하기
lower_case = letters_only.lower()
# 문자를 공백을 기준으로 나눈다 => 토큰화
words = lower_case.split()
print(len(words))
words[:10]
# 437
# ['with',
# 'all',
# 'this',
# 'stuff',
# 'going',
# 'down',
# 'at',
# 'the',
# 'moment',
# 'with']
불용어 제거(Stopword Removal)
일반적으로 코퍼스에서 자주 나타나는 단어는 학습 모델이나 학습 및 예측 프로세스에 별로 도움이 안된다.
예를 들어, 조사, 접미사, i, me, my, this, that, is, are 등과 같은 단어는 빈번하게 등장하긴 하지만, 실질적인 의미를 지니고 있지 않기 때문이다.
Stopwords는 “to” 또는 “the”와 같은 용어를 포함하므로 사전 처리 단계에서 제거하는 것이 좋다.
NLTK에는 153개의 영어 불용어가 미리 정의되어 있다.
(17개의 언어에 대해 정의되어 있으며, 한국어는 포함되지 않는다.)
`NLTK(Natural Language Toolkit) : 자연어 처리 및 문서 분석용 파이썬 패키지
import nltk
from nltk.corpus import stopwords
stopwords.words('english')[:10]
# ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your']
NLTK를 이용해서 불용어 처리하기
# stopwords를 제거한 토큰들
words = [ w for w in words if not w in stopwords.words('english')]
print(len(words))
# 219
words[:10]
# ['stuff',
# 'going',
# 'moment',
# 'mj',
# 'started',
# 'listening',
# 'music',
# 'watching',
# 'odd',
# 'documentary']
앞에서 볼 수 있었던 this, with, all과 같은 단어들이 사라진것을 확인할 수 있다.
스테밍(어간추출, 형태소 분석)
어간 추출(stemming은 형태론 및 정보 검색 분야에서 어형이 변형된 단어로부터 접사 등을 제거하고 그 단어간의 어간을 분리해내는것을 의미한다.
“message”, “messages”, “messaging”과 같이 복수형, 진행형 등의 문자를 같은 의미의 단어로 다룰 수 있도록 도와준다.
참조
어간 추출에는 NLTK에서 제공하는 형태소 분석기를 사용하고, 포터(Porter) 형태소 분석기와 랭커스터(Lancaster)가 있음.
Poter Stemmer 사용
stemmer = nltk.stem.PorterStemmer()
print("The stemmed form of running is : {}".format(stemmer.stem("running")))
# The stemmed form of running is : run
print("The stemmed form of runs is : {}".format(stemmer.stem("runs")))
# The stemmed form of runs is : run
print("The stemmed form of run is : {}".format(stemmer.stem("run")))
# The stemmed form of run is : run
Lancaster Stemmer 사용
from nltk.stem.lancaster import LancasterStemmer
lancaster_stemmer = LancasterStemmer()
from nltk.stem.lancaster import LancasterStemmer
lancaster_stemmer = LancasterStemmer()
print("The stemmed form of running is : {}".format(stemmer.stem("running")))
# The stemmed form of running is : run
print("The stemmed form of runs is : {}".format(stemmer.stem("runs")))
# The stemmed form of runs is : run
stemming 전 단어들을 확인해보자
words[:10]
# ['stuff',
# 'going',
# 'moment',
# 'mj',
# 'started',
# 'listening',
# 'music',
# 'watching',
# 'odd',
# 'documentary']
from nltk.stem.snowball import SnowballStemmer
stemmer = SnowballStemmer('english')
words = [ stemmer.stem(w) for w in words ]
# 처리 후 단어
words[:10]
# ['stuff',
# 'go',
# 'moment',
# 'mj',
# 'start',
# 'listen',
# 'music',
# 'watch',
# 'odd',
# 'documentari']
Lemmatization 음소표기법
다음 문장들을 살펴보자.
1) 배가 맛있다.
2) 배를 타는 것이 재미있다.
3) 평소보다 두 배로 많이 먹어서 배가 아프다.
위의 3개의 문장에서 “배”는 모두 다른 의미를 갖는다.
음소표기법은 이때, 앞뒤 문맥을 보고 단어의 의미를 식별하는 것이다.
영어에서 meet은 meeting으로 쓰였을때, 회의를 뜻하지만 meet일때는 만나다는 뜻을 가지는데, 그 단어가 명사로 쓰였는지 동사로 쓰였는지에 따라 적합한 의미를 추출하는것으로 보면 된다.
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
print(wordnet_lemmatizer.lemmatize('fly'))
# fly
print(wordnet_lemmatizer.lemmatize('flies'))
# fly
words = [ wordnet_lemmatizer.lemmatize(w) for w in words]
# 처리 후 단어
words[:10]
# ['stuff',
# 'go',
# 'moment',
# 'mj',
# 'start',
# 'listen',
# 'music',
# 'watch',
# 'odd',
# 'documentari']
문자열 처리
위에서 살펴본 내용을 바탕으로 문자열을 처리해본다.
def review_to_words(raw_review):
#1. HTML 제거
review_text = BeautifulSoup(raw_review, 'html.parser').get_text()
#2. 영문자가 아닌 문자는 공백으로 변환
letters_only = re.sub('[^a-zA-Z]', ' ', review_text)
#3. 소문자 변환 후 공백으로 토크나이징
words = letters_only.lower().split()
#4. 파이썬은 리스트보다 세트로 찾는게 훨씬 빠름
stops = set(stopwords.words('english'))
#5. Stopwords 불용어 제거
meaningful_words = [w for w in words if not w in stops]
#6. 어간 추출
stemming_words = [stemmer.stem(w) for w in meaningful_words]
#7. 공백으로 구분된 문자열로 결합하여 결과를 반환
return(' '.join(stemming_words))
clean_review = review_to_words(train['review'][0])
clean_review

이제, 첫번째 리뷰를 대상으로 전처리 진행했던 것을전체 텍스트를 대상으로 처리한다.
우선, 전체 리뷰가 몇개가 존재하는지 확인해본다.
num_reviews = train['review'].size
num_reviews
# 25000
전체 데이터에 대한 전처리 과정을 진행할 경우 상당한 시간이 소요된다.
참조를 통한 멀티프로세싱 모듈을 사용해서 실행속도를 개선시키도록 한다.
from multiprocessing import Pool
import numpy as np
def _apply_df(args):
df, func, kwargs = args
return df.apply(func, **kwargs)
def apply_by_multiprocessing(df, func, **kwargs):
# 키워드 항목 중 workers 파라메터를 꺼냄
workers = kwargs.pop('workers')
# 위에서 가져온 workers 수로 프로세스 풀을 정의
pool = Pool(processes=workers)
# 실행할 함수와 데이터프레임을 워커의 수 만큼 나눠 작업
result = pool.map(_apply_df, [(d, func, kwargs)
for d in np.array_split(df, workers)])
pool.close()
# 작업 결과를 합쳐서 반환
return pd.concat(list(result))
트레이닝 데이터 전처리
%time clean_train_reviews = apply_by_multiprocessing(\
train['review'], review_to_words, workers=4)
테스트 데이터 전처리
%time clean_test_reviews = apply_by_multiprocessing(\
test['review'], review_to_words, workers=4)
생각보다 시간이 꽤 (매우 많이) 걸린다..
워드 클라우드
워드 클라우드는 단어의 빈도 수 데이터를 가지고 있을때, 이용할 수 있는 시각화 방법
단순히 빈도수를 표현하기 보다는 상관관계나 유사도 등으로 배치하는게 더 의미있기 때문에 큰 정보를 얻기에는 한계가 있다.
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
# %matplotlib inline 설정을 해주어야지만 노트북 안에 그래프가 디스플레이 된다.
%matplotlib inline
def displayWordCloud(data = None, backgroundcolor = 'white', width=800, height=600 ):
wordcloud = WordCloud(stopwords = STOPWORDS,
background_color = backgroundcolor,
width = width, height = height).generate(data)
plt.figure(figsize = (15 , 10))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
학습 데이터의모든 단어에 대한 워드 클라우드를 그려본다.
%time displayWordCloud(' '.join(clean_train_reviews))
Subscribe via RSS