데이터 사이언스 기초지식 - 01
by EunHye Jung
- 데이터 과학 = 데이터베이스 + 통계학 + 머신러닝 기타 등등
- 데이터사이언스에서 제일 중요한 개념은
변수,
데이터를 가지고 궁극적으로 알고싶은게 뭔지질문이 있어야함.
예측 분석(Predictive Analysis)
-
A에 따라 B가 어떻게 달라지는가? (예를 들어 A는 마케팅 B는 매출, 혹은 A는 다이어트 전략 B는 체중감량정도로 볼 수 있음)
여기서 A는독립변수, B는종속변수가 됨.
(A에따라 B는 달라지고, B는 A에 종속되어 있음) - 가장 단순한 에측분석으로는
단순 회 분석(Simple Regression Analysis)이 있음.
가장 오래되고 많이 쓰이며, 하나의 변수로 하나의 변수를 예측하는 기법. - 여러개의 변수로 하나의 변수를 예측하는 기법으로는
중다 회귀 분석(Multiple Regression Analysis)이 있음. - 일반적으로 단순회귀분석과 중다회귀분석을 딱히 구분하지는 않음.
독립변수를 가지고 종속변수를 예측하는데 이게 어떤 직선의 형태로 예측한다 라는걸 일반적으로 회귀분석이라고함. -
회귀분석은 일반적으로
연속적인종속변수를 예측하고자할때 쓰인다. -
연속적인 변수를 예측하는것의 반대는
이산(discrete) = 범주형(categorical)예측이 있다.
이산값을 예측하는 분석을분류분석(classification)이라고 한다. -
이렇게 예측분석을 크게 나누면 연속적인 값을 예측하는
회귀분석과 이산적인것을 예측하는분류분석으로 나뉜다.
예를 들어, 고객정보(나이, 성별 등)으로 물건의 구매여부를 예측하고 싶다면 이건 이산적인것을 예측한것에 속한다. (물건을 살지말지는 분류의 개념에 속하기 때문임)
텍스트 분서겡서 고객리뷰의 단어 사용 빈도에 따라 만족/불만족을 판정하는 것도 분류 분석에 해당되며, 감정 분석(sentimental analysis)라고도 불린다.
분류분석의 원리
-
회귀분석은 어떤 데이터가 있을때 그 데이터의 추세선을 찾는것이다.
분류분석은 경계선을 찾아서 분석한다.
경계선은 다양하게 그어질 수 있는데, 이 경계선이 어떻게 그어지느냐에 따라서 예측 결과값이 달라질 수 있다.
경계선을 긋는 방법에 따라서 분류분석이 여러 방법들로 나눠진다.만약에 식이조절 강도(육식 줄이고 채식 많이많이)와 운동량에 따른 다이어트의 성공유무를 예측하고자 한다.
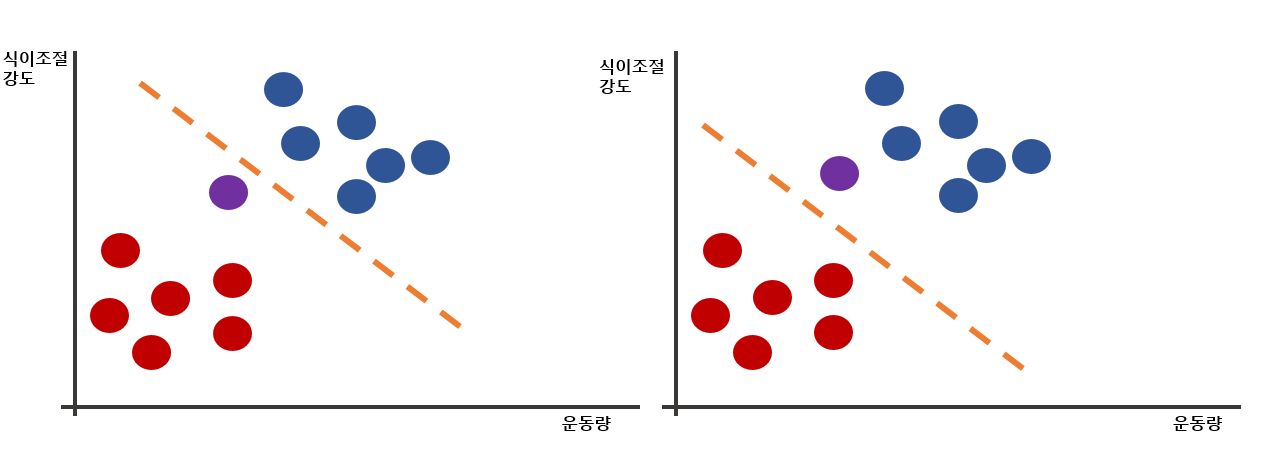
위 그림을 살펴보면, 운동량도 많고, 식이조절도 잘한 다이어트의 성공한 집단(파랑점들의 모음)이 있고, 운동량 저조와 식이조절에 실패에 다이어트에 실패한 집단이(붉은점들의 모음)있다.
보라색점의 다이어트의 성공 여부를 판단하고자 할때 왼쪽그림처럼 경계선을 긋는경우 다이어트실패라는 예측값을 내놓고, 오른쪽선처럼 경계선을 긋는경우 다이어트성공이라는 예측값을 내놓게 될것이다.
분류분석의 방법들
- 분류분석의 방법들로는 판별분석, 로지스틱회귀분석, 의사결정나무, SVM, 딥러닝 등의 방법들이 있다.
실제로 예측에는 여러가지 분석방법들을 이용해서 예측이 제일 잘되는 방법을 사용한다.
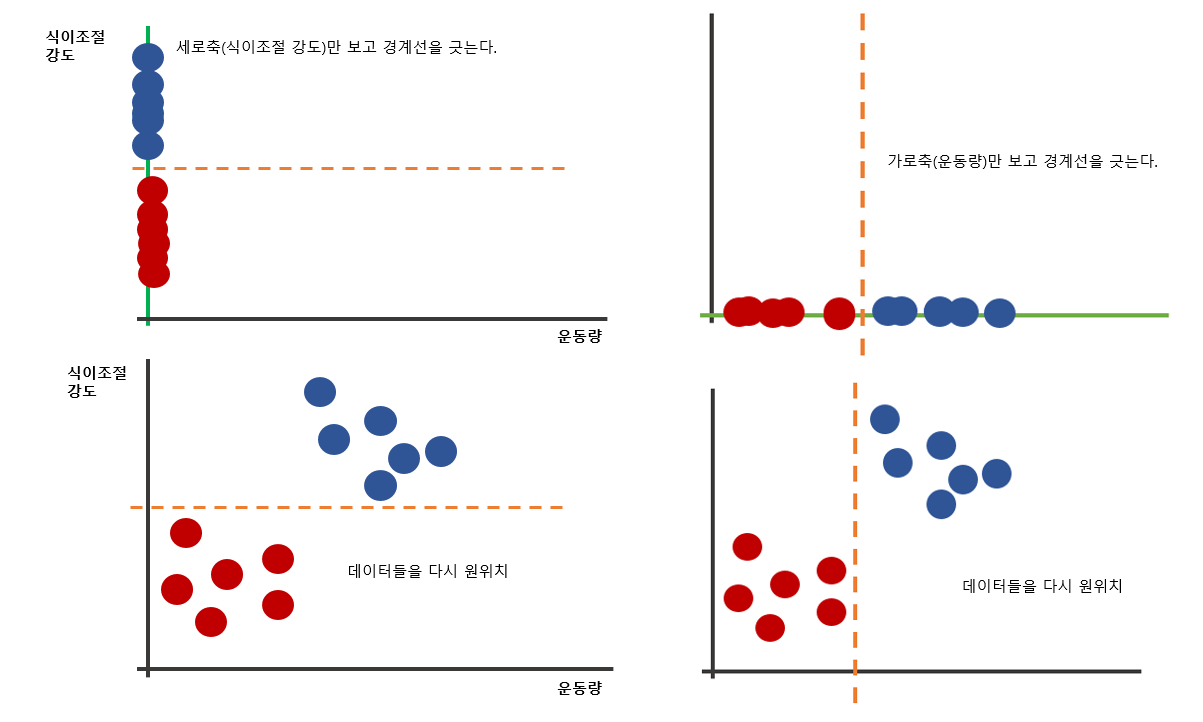
판별분석
- 판별분석은 데이터를 하나의 축으로 다 옮긴다음에, 그 축에서 경계선을 긋는 방법이다.
(경계선을 긋기 쉬운 축을 찾아서 경계선을 그으면 된다.)
로지스틱 회귀분석 (Logistic Regression Analysis)
- 회귀분석으로 분류분석 : 확률을 예측(확률은 연속적인값을 나타냄)
회귀분석에서 트릭을 써서 분류분석하는 기법
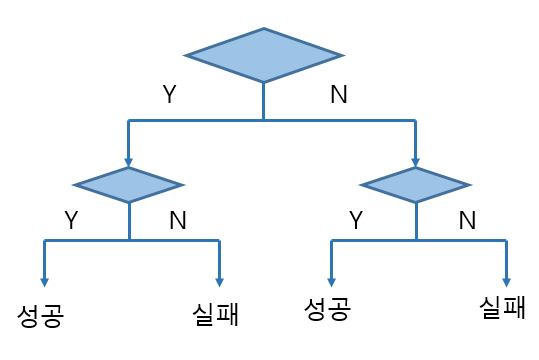
의사 결정 나무 (Decision Tree)
- 수많은 데이터를 가지고 컴퓨터가 데이터를 분류하는 가장 좋은 질문들을 찾아내준다.
채식량이 많은가? 운동울 주3회이상하는가? 이런 질문을 바탕으로 답을 찾아나간다고 생각하면됨.
직관적이고 트리만 보아도 사람이 결과를 예측할 수 있다.
하지만, 데이터가 조금만 달라지면 전체적인 트리구조가 급격히 달라지며, 결과값이 불안정하다.
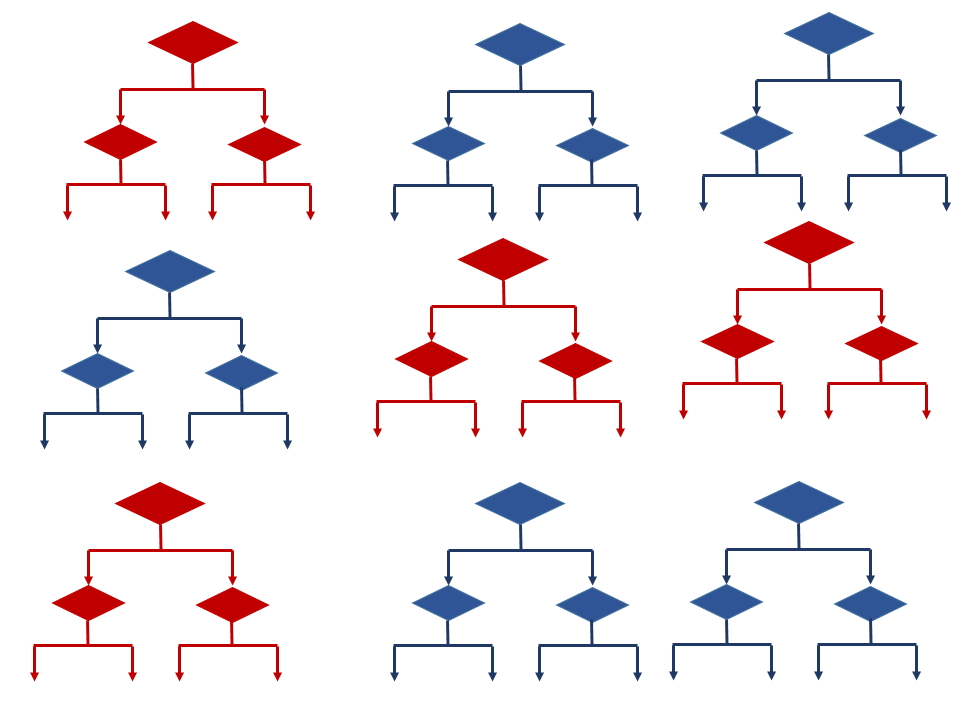
랜덤 포레스트 (Random Forest)
- 데이터의 일부만 랜덤하게 뽑아서 의사결정 나무를 만든다.
이 과정을 반복해서 의사결정 나무를 많이많이 만든다.
그리고 의사결정 나무들에게서 나온 전체값을 기반으로 최종값을 도출해낸다.
의사결정나무는 하나하나 불안정한 결과값을 가지지만 전체적으로 보면 안정된 값을 취한다.
단순한 방법이지만, 상당히 예측값이 잘나오는 방법이라 현재에도 두루두루 쓰이고 있음.
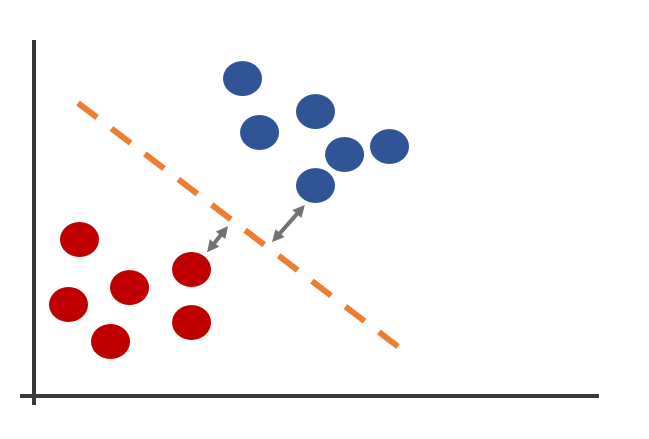
서포트 벡터 머신 (Support Vector Machine, SVM)
- 판별분석에서 경계선을 찾을때는 데이터 전체를 가지고, 데이터들을 구분해주는 경계선을 찾았었다.
SVM에서는 경계선에서 가장 가까운 데이터만 가지고 그 데이터와 가장 거리가 먼 경계선을 찾는다.
경계선과 데이터간의 거리를 서포트 벡터(Support Vector)라고 한다.
정확도가 높은 분석방법이라 실제로 많이 쓰이고 있다.
예측분석, 어떤 방법을 써야할까?

- 데이터량이 많을때
데이터량이 많을때는 일반적으로 랜덤포레스트, SVM, 딥러닝 방법을 이용한다.
데이터가 적을때 오히려 랜덤포레스트와 딥러닝은 예측률이 떨어진다. 특히 딥러닝의 경우 매우매우 많은양의 데이터가 필요하다. -
해석이 필요할때
회귀분석은 값이 공식으로 떨어진다. 종속변수(결과)가 왜그렇게 나왔는지 설명할 수 있다.
하지만 런덤포레스트나 딥러닝은 매우 복잡한 과정을 통해 나오는 결과이기 때문에 예측을 결과물로 내놓기는 하지만 그게 어떻게 나왔는지 설명해주지는 못한다. - 예를들어, 앞에서 다이어트의 성공할 수 있는 코스를 추천해주는 시스템이 있다고 하자.
정말 단기간에 기필코 다이어트에 성공해야 하는 사람은 이 코스가 어떻게 구성되어있는지는 궁금하지 않다. 단순히 성공할 수 있느냐 없느냐에만 집중할것이다. (이런 경우 랜덤포레스트, SVM, 딥러닝 분석이 쓰임)
하지만 건강한 다이어트를 원하는 사람은 다이어트 코스가 어떻게 구성되어있는지 궁금할것이다. 어떻게 운동을 하는지 식단조절은 어떻게 하는지 세세히 궁금한 사람들은 회귀분석을 이용한다.
결과적으로 딥러닝은 단순히 성공여부만 예측은 가능하나 어떻게 성공했는지는 설명해주지 못한다.
Subscribe via RSS