Scikit Learn, 지도학습, RMSLE, 교차검증
by EunHye Jung
Scikit Learn
-
파이썬으로 머신러닝할때, 사이킷런을 주로 사용함.
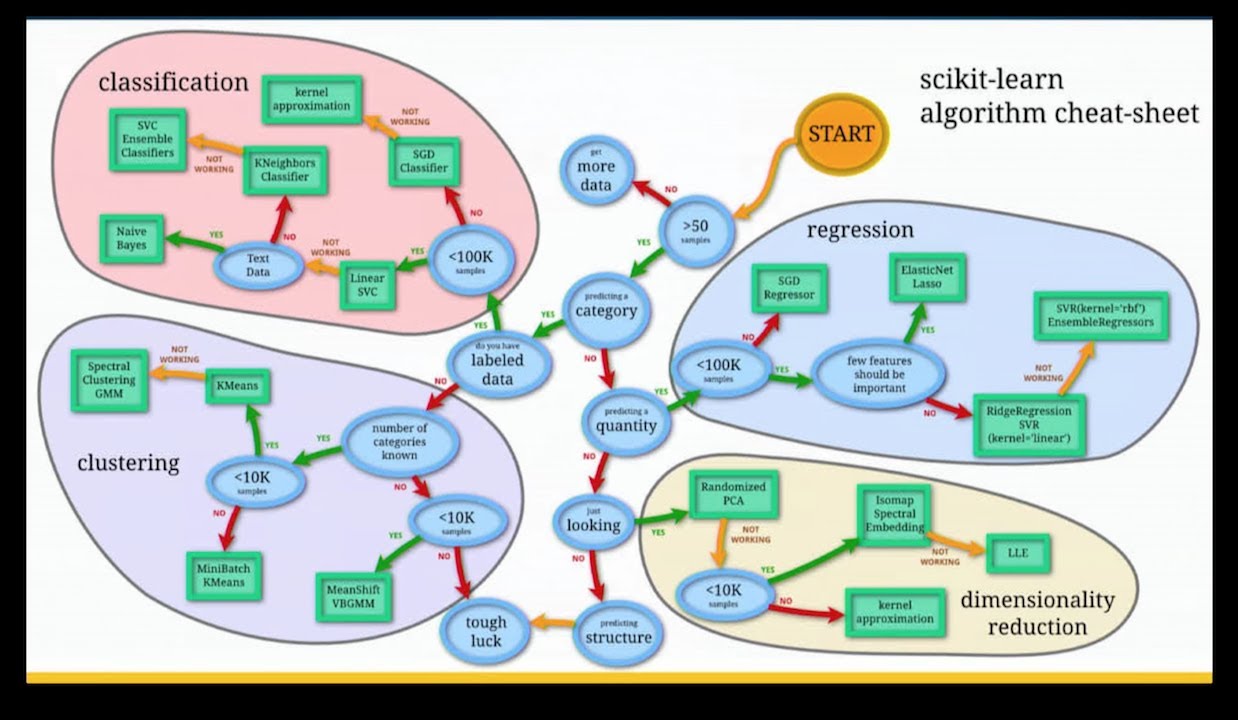
분류같은 경우는 대표적으로 kaggle 타이타닉 생존여부를 예측하는 문제가 속하고,
자전거 대여 수요예측은 시계열 데이터를 기반으로 그 상황에서 자전거 데이터 수요예측을 하기때문에 회귀분석에 해당
Supervised Machine Learning(지도학습)
-
지도학습과 비지도학습을 나누는 가장 큰 기준은 레이블(label)된 데이터가 있느냐 없느냐.
랜덤 포레스트를 이용해서 예측하는 과정을 살펴본다면
clf = RandomForestClassifier() # 분류기를 가져옴 cif.fit(X_train, y_train) # 학습시킴 y_pred = clf.predit(X_test) #예측 clf.score(X_test, y_test) # 점수를 냄
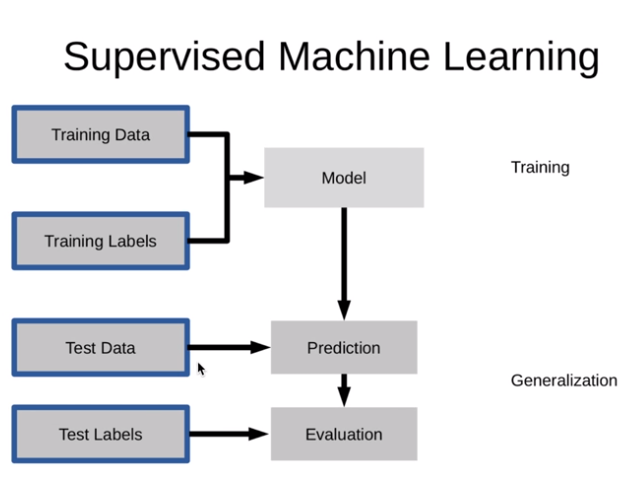
Overfitting and Underfitting
- 과대적합(Overfiting)
너무 복잡한 모델을 만들어 일반화하기 어려움. (ex) feature가 너무많은것) - 과소적합(Underfiting)
너무 간단한 모델이 선택되어 데이터의 특징과 다양성을 잡아내지못함.
RMSLE
- 과대평가된 항목보다는 과소형가된 항목에 패널티를 준다.
-
오차(Error)를 제곱(Square)해서 평균(Mean)한 값의 제곱근(Root)으로 값이 작을수록 정밀도가 높다.
0에 가까울수록 정밀도가 높은값이다.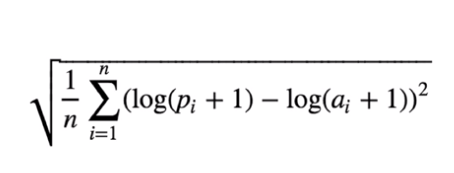
n : number of hours in the test set
pi : predicted count
ai : actual countfrom sklearn.metrics import make_scorer def rmsle(predicted_values, actual_values): # 넘파이로 배열 형태로 바꿔줌. predicted_values = np.array(predicted_values) actual_values = np.array(actual_values) # 예측값과 실제 값에 1을 더하고 로그를 씌어줌 log_predict = np.log(predicted_values + 1) log_actual = np.log(actual_values + 1) # 위에서 계산한 예측값에서 실측값을 빼주고 제곱해줌 difference = log_predict - log_actual difference = np.square(difference) # 평균을 냄 mean_difference = difference.mean() # 다시 루트를 씌움 score = np.sqrt(mean_difference) return score
Cross Validation 교차검증
- 일반화 성능을 측정하기 위해 데이터를 여러번 반복해서 나누어 여러 모델을 학습함.
- KFold 교차검증
데이터를 폴드라 부르는 비슷한 크기의 부분집합(n_splits)으로 나누고 각각의 폴드 정확도를 측정.
첫번재 폴드는 테스트 세트로 사용하고, 나머지 폴드를 훈련세트로 사용하여 학습
나머지 훈련세트로 만들어진 세트의 정확도를 첫번째 폴드로 평가
다음은 두번째 폴드가 테스트세트가 되고 나머지 폴드의 훈련세트를 두번째 폴드로 정확도를 측정.
이 과정을 마지막 폴드까지 반복.
이렇게 훈련세트와 테스트세트로 나누는 N개의 분할, 정확도를 측정하여 평균값을 낸게 정확도가 됨.
Subscribe via RSS